

随着“一带一路”的提出,中越两国共同关注的问题日益增多,相关的新闻报道也随之增多.及时检测越南语新闻中的新闻事件有助于把握新闻导向,获取越南的舆情动态,并作出有效应对.事件检测是自然语言处理的重要信息提取任务,旨在识别文本中指定类型的事件.目前,事件检测研究大都在汉语、英语环境下展开,由于越南语属资源稀缺型语种,针对越南语的事件检测暂无人涉及.因此,本文针对越南语领导人出行领域新闻事件进行检测.
事件检测主要由两部分子任务组成:(1)触发词的检测,识别出句子中的触发词;(2)根据触发词进行分类,确定事件句所表示的事件类型[1].分析越南语的构词特点,每一个音节常常是一个有意义的单位,可以独立使用,每个单词又可作为构成多音节词的基础,绝大部分多音节词是双音节,在进行触发词识别时会存在歧义的问题,触发词在不同文本中属于不同事件类型.例如:
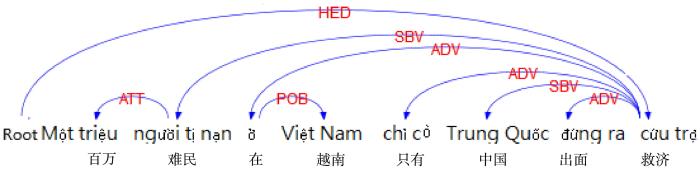
S1:Một triệu người tị nạn ở Việt Nam,chỉ có Trung Quốc đã đứng ra cứu trợ.
译文:越南百万难民,只有中国出面救济.
S1中虽然包含出席活动事件的触发词“đứng ra(出面)”,但通过对事件句的分析可知,事件句中并不包含出席活动事件.事件检测的准确性主要依赖于对触发词的正确识别和事件句语义信息的充分理解.
目前大多是采用深度学习来进行事件检测,可以充分提取事件句的局部特征.但由于越南语独特的语言特征,如句法结构中主语在谓语之前、宾语和补语在动词之后、名词修饰语一般在名词之后,但数词、量词修饰语在名词之前、定语要放在所修饰的中心词之后等[2],相隔较远的词之间的信息难以捕获.S1中,通过“đứng ra(出面)”的前后词“Trung Quốc(中国)”“cứu trợ(救济)”以及“cứu trợ(救济)”和“người tị nạn(难民)”,这些语义信息就可以帮助判定“đứng ra(出面)”并非领导人出席活动的触发词.
1 相关工作
目前事件检测任务主要基于两类方法:(1)机器学习方法.张炫[5]提出以狄利克雷过程事件混合模型(Dirichlet Process Event Mixture Model,DPEMM)为核心的事件抽取框架.裴东辉[6]提出基于支持向量机模型的子事件类别自动识别.高永兵等[7]针对微博的特征进行TF⁃IDF(Term Frequency⁃Inverse Document Frequency)的改进得出事件提取结果.(2)深度学习方法.与机器学习方法相比,神经网络能自动学习构建特征,可以避免繁琐的特征工程.Nguyen et al[8]在已有研究的基础上提出一种基于递归神经网络的联合方法进行英文事件抽取.Chen et al[9]提出动态多池卷积神经网络(Dynamic Multi⁃Pooling Convolutional Neural Network,DMCNN),解决了句中多个事件的识别以及共享参数匹配的问题.Nguyen and Grishman[10]使用卷积神经网络对句中的词进行卷积以获得句中隐含的语义信息.但这种连续的卷积无法解决信息依赖问题,有时相隔较远词之间的语义特征反而会有助于事件检测.Nguyen and Grishman[11]提出NCNN(N⁃Gram Convolutional Neural Network)模型对句子中所有非连续的n个词进行卷积来解决这个问题,但考虑所有的非连续n个单词可能会捕捉到不必要的信息.随着图卷积(Graph Convolutional Networks,GCNs)[12,13,14]的提出,Nguyen and Grishman[15]提出基于依存信息的图卷积神经网络和基于实体提及的池化方法用于事件检测,该方法对依存句法信息进行图卷积,解决句中非连续词之间的信息依赖问题.但Nguyen的方法只捕获有句法信息的词之间的关系,忽略了连续词之间的语义信息.
通过分析越南语的语言特性,本文提出融合依存句法信息的卷积神经网络(Dependency Parsing Convolutional Neural Networks,DPCNN)模型,同时采用传统卷积神经网络和融合依存信息的卷积神经网络获取连续词之间的语义信息和相隔较远的词之间的语义信息,既挖掘句子的深层语义信息又避免冗余信息的获取.
2 相关定义
本文对事件的定义如下:
(1)事件:在特定的时间和环境下发生、由若干个角色参与,表现出动作特征的一件事情,由事件触发词与事件参数构成.
(2)事件触发词:能清楚地表达一类事件发生,是触发事件的主要词,通常是单个动词或者名词.例如“Truy cập(出访)”“Tham dự(出席)”“Đềxuất(提出)”“Cuộc họp(会见)”.
(3)事件参数:描述事件发生的时间、地点、人物等信息.
(4)事件类型:将越南语领导人活动新闻事件分为“出访国家”“出席会议”“出席活动”“重要讲话”等五个事件类型和一个非事件类型,其中每个事件类型与多个触发词对应,例如“Đi thăm(访问)”和“Ghé thăm(拜访)”均为“Ra ngoàitruy cập(外出访问)”的触发词.
3 方 法
本文将事件检测问题转化为多分类问题,以此来判断句子中是否存在新闻事件,若存在则指出其事件类型.提出的DPCNN由三个部分组成:编码层、卷积层和池化层,如图1所示.
图1
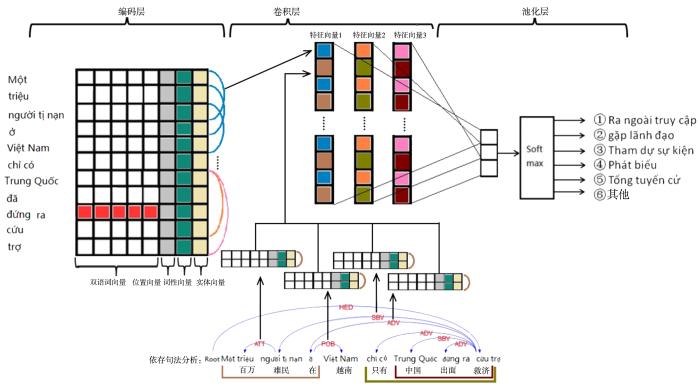
3.1 编码层
首先将句子中的词级信息转换成实值向量作为神经网络的输入.设
词向量是一个实值向量,目前有两种常用的表示方式:一种是one⁃hot表示,创建一个词表,并把每个词顺序编号;另一种是基于分布式的词向量.本文采用Mikolov et al[17]提出的word2vec模型训练方法训练越南语词向量.
由于位置编码可以引入当前词的语义结构信息,本文将位置编码作为编码的一部分,指当前词与触发词的相对位置.例如,S1中“đứng ra(出面)”和“người tị nạn(难民)”之间的相对位置为6.
由于词性和实体类型有助于获取当前的词语意信息,依据侯中熙和杨蓓[18]提出的方法对越南语进行词性标注,并定义词性嵌入表,将28种词性标签嵌入到词性向量中.
与词性向量类似,依据刘艳超等[19]提出的方法对越南语进行命名实体识别,定义实体嵌入表,识别出句子中的人名、地名、组织机构名、时间等命名实体,将实体标签嵌入到实体向量中.共有十种实体类型,分为三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比).
3.2 卷积层
卷积层可以捕获整个句子的组合语义信息,并将这些有价值的语义压缩到特征映射中.卷积运算中最重要的一个部分就是滤波器w,它可以提取卷积窗内词之间的特征.当卷积核大小为m时,窗口内的m个词
其中,b(b∈R)是偏置项,f是非线性激活函数,滤波器应用于句子中每个可能的窗口
图2
卷积运算可以捕获窗口内连续词之间的语义信息,却不能捕获窗口外非连续词的特征.本文通过依存句法分析引入窗口外的信息,依存信息用
(p≤n)表示句中存在依存关系的所有词节点,有依存关系的两词节点用xs,t表示,E是两词节点之间边,每个边(xs,xt)代表从词节点xs指向词节点xt,并且有依存信息标签L(xs,xt).例如,图2中节点“cứu trợ(救济)”和“người tị nạn(难民)”之间的有向边依存信息标签为L(xs,xt)=L(cứu trợ,người tị nạn)=Datv. Kipf and Welling[12]提出的方法表示信息流不只是按照标签指示的方向,因此这里添加了自循环(xs,xs)和反向边(xt,xs).自循环的标签为L(xs,xs),反向边的标签为L^(xt,xs).特定的依存信息标签具有固定的参数,依存特征的计算如下:
其中,j的范围是1到k,f为非线性激活函数,
E∈Rk(n-m+1)为卷积得到的结果矩阵,k为滤波器的个数,n为句子长度,m为滤波器窗口大小.
3.3 池化层
池化层可以提取卷积特征中的最具代表性的特征.本文选取最大池化的方法如式(5)所示:
k个滤波器,提取每个滤波器中最有价值的局部特征,其他特征值全部抛弃,k个局部特征聚合成一个向量E*作为事件编码.最后,将事件编码送入全连接层,使用softmax激活函数对E*进行分类,得到事件的分类概率,根据概率分布对事件的类型进行预测,如式(6)所示:
其中,C表示类别个数,i表示类别索引i的范围是1到6.
4 实 验
4.1 实验设计
目前为止尚未有可供公开测评的越南语事件检测的语料库.实验语料来源于东南亚舆情分析平台,参考ACE (Automatic Content Extraction)的事件标注体系对语料进行标记,经过去重、筛选以后标注了领导人出行活动领域的越南语新闻文本1233篇,共9576条事件句.将8069条事件句作为训练数据,1507条事件句作为测试集.本文构建的语料中划分了五种事件类型和一种非事件类型,分别为外出访问、领导会见、出席会议、出席活动、发表讲话和无事件类型,对应的触发词如表1所示.
表1 触发词表
Table 1
| 事件类型 | 事件触发词 |
|---|---|
Ra ngoàitruy cập 外出访问 | Đi thăm,Ghé thăm,Truy cập,Nhiệm vụ,Kiểm tra 拜访,访问,出访,走访,探问,考察,探访… |
gặp lãnh đạo 高层会见 | Họp,Gặp gỡ,Nói chuyện,Tiếp kiến,Gặp nhau,Gặp mặt,Hội đàm 会见,接见,见面,会晤,会谈… |
Tham dựsựkiện 出席活动 | Tham dự,Đi ra,Tham gia,Sắp xếp,Đến rồi,Tại cuộc họp 出席,出面,参加,列席,到场,到会… |
Phát biểu 发表讲话 | Bài giảng, xuất bản, nói, trình bày, phát biểu, đề nghị, nói chuyện 演讲,发表,发言,提出,讲话,谈话… |
Tổng tuyển cử 换届选举 | Đề nghị, bỏ phiếu, Giới thiệu, bầu cử 推举,选举,推选,投票竞选… |
模型用Tensorflow深度学习框架实现.使用固定长度为25的句子作为输入,即句子长度大于25时截取前25个词,句子长度不足25时则使用特殊字符填充.使用253维的预训练词嵌入,位置嵌入1维,词性嵌入1维,实体类型嵌入1维.本模型采用两层卷积,每层卷积有三个滤波器,共三个卷积通道,卷积核大小分别为3,4,5,卷积步长为1,边界采用全0填充.初始学习率为0.01,使用交叉熵作为损失函数,采用反向传播和Adam优化算法训练模型,随机失活率50%,batch⁃size 50,epoch 50,衰减系数0.96.为了防止过拟合,在分类时加入L2正则项,其系数为3.
4.2 对比实验
采用准确率(P)、召回率(R)和F值(F)作为评价指标.
其中,A为正确识别事件类型的数量,B为错误识别事件类型的数量,C为未被识别到的正确识别事件类型的数量.
4.2.1 卷积层数探究
为探究卷积层数对实验结果的影响,分别采用一层、两层和三层卷积的模型进行实验,找到最优层数.实验结果如表2所示.
表2 卷积层数对实验结果的影响
Table 2
| 卷积层数 | P | R | F |
|---|---|---|---|
| 1 | 74.04% | 62.63% | 70.08% |
| 2 | 76.78% | 64.25% | 71.45% |
| 3 | 75.53% | 59.01% | 68.23% |
由表2可见,当卷积层数为2时效果最佳,准确率、召回率和F值分别为76.78%,64.25%,71.45%.而当卷积层数为3时,模型的性能却有所下降.因此后续实验中模型均采用两层卷积.
4.2.2 编码特征探究
针对词嵌入层融入的编码特征进行探究.在去掉某一项编码向量之后,剩余的两类编码向量和词向量融合作为模型的输入,探究不同编码特征组合对模型性能的影响.实验结果如表3所示.
表3 编码特征对实验结果的影响
Table 3
| 编码特征 | P | R | F |
|---|---|---|---|
词向量、位置向量、 词性向量和实体向量 | 76.78% | 64.25% | 71.45% |
词向量、词性向量和 实体向量 | 74.23% | 62.3% | 69.2% |
词向量、位置向量和 实体向量 | 71.88% | 63.4% | 69.3% |
词向量、位置向量和 词性向量 | 73.46% | 64.02% | 69.97% |
由表3可知,去掉某一项编码向量之后,模型的准确率、召回率、F值与本文模型相比均有所下降,所以同时使用三种编码向量可以提高事件检测的性能.
4.2.3 卷积核大小探究
为探究卷积核大小对模型的影响,分别采用不同大小的三个卷积核获取特征向量,实验结果如表4所示.
表4 卷积核大小对实验结果的影响
Table 4
| 卷积核大小 | P | R | F |
|---|---|---|---|
| 2,3,4 | 73.21% | 63.59% | 66.73% |
| 3,4,5 | 76.78% | 64.25% | 71.45% |
| 4,5,6 | 75.07% | 61.22% | 70.88% |
| 5,6,7 | 73.12% | 62.25% | 67.54% |
由表4可知,当卷积核为3,4,5时模型效果最佳.较小和较大的卷积核均会降低模型的性能.
4.2.4 不同模型的探究
表5 不同模型的性能对比
Table 5
| 模型 | P | R | F |
|---|---|---|---|
| RNN | 70.23% | 65.89% | 67.23% |
| CNN | 73.23% | 63.14% | 69.23% |
| GCNs | 75.00% | 63.92% | 70.24% |
| DPCNN | 76.78% | 64.25% | 71.45% |
由表5可知,卷积神经网络的模型均优于循环神经网络模型,其中DPCNN和GCNs的模型效果优于CNN,DPCNN优于GCNs.由于循环神经网络存在长距离依赖的问题,会影响事件的准确检测,而引入依存句法信息可以捕获到CNN没有捕获到的信息.GCNs和DPCNN相比,可以看到DPCNN的F值提升了1.21%,说明大部分信息可以被GCNs所捕获,但同时使用连续的卷积神经网络和融合依存句法信息的卷积神经网络则可以捕获到句中更多的隐含信息.
5 结 论
本文提出一种越南语新闻事件检测的新型神经网络模型,该模型融合词向量、位置向量、词性向量和命名实体向量来捕捉词级别的语义信息,同时使用传统的卷积神经网络和融合依存句法信息的卷积神经网络获取句子级别语义信息.通过对模型设置不同的参数,将最佳模型与基线方法作比较,证明本文提出的方法在越南语新闻事件的检测中得到较好的效果.但由于越南语的语料尚不完善,本文提出的模型在越南语新闻事件检测任务上仍有提升空间.事件检测是事件抽取的重要环节,后期可在一个模型中同时识别出事件触发词和事件参数,从而实现事件抽取的任务.
参考文献
ACE (Automatic Content Extrac⁃tion) Chinese annotation guidelines for events,version5.5.1.
基于依存句法分析与分类器融合的触发词抽取方法
Trigger extraction algorithm based on dependency parsing and classifier fusion
Structural parse tree features for text representation
∥
微博事件抽取
中文新闻事件抽取方法研究
基于个人微博特征的事件提取研究
Research on event extraction based on personal microblog characteristics
Joint Event extraction via Recurrent Neural Networks
∥
Event Extraction via dynamic multi⁃pooling convolutional neural networks
∥
Event detection and domain adaptation with convolutional neural networks
∥
Modeling Skip⁃Grams for event detection with convolutional neural networks
∥
Semi⁃supervised classification with graph convolutional networks
∥
Encoding sentenceswith graph convolutional networks for semantic role labeling
∥
Molecular graph convolutions:moving beyond fingerprints
Graph convolutional networks with argument⁃aware pooling for event detection
∥
Exploiting argument information to improve event detection via supervised attention mechanisms
∥
Efficient estimation of word representations in vector space
∥
基于SVMTooL的越南语词性标注
融合实体特性识别越南语复杂命名实体的混合方法
A hybrid method for identifying Vietnamese complex named entities by merging entity features

{kind=link}
{kind=link}
{kind=link}
{kind=link}