

语音识别是人工智能一个重要的研究方向,其中语音情感识别在人机交互语领域有重要的作用.不同语料库的语音情感往往存在差异性,但也包含情感的相似性.单个语言的情感探究无法对不同的语言情感进行比较研究.在跨语料库的语音情感识别中,研究者们主要关注的是提高情感识别率算法,对不同的语音情感相似性和差异性的研究较少.因此本研究对不同语料库的语音情感识别进行探究.
对不同语言的情感识别研究成果丰富,主要是通过不同的语音数据库进行人工情感判断的方法来探究不同语言的情感识别差异[7,8,9].Paulmann and Uskul[10]录制中文和英文的情感数据库进行情感识别探究,发现中国参与者的跨语言情感识别好于英国参与者.Koeda et al[11]探究英语、德语、印地语和阿拉伯语情感识别,得到情感存在相似混淆模式和特征差异性.Sauter et al[12]发现负面的情感比积极的情感更容易在跨语言的条件下被识别.但以前的研究大都基于人工听语音来分辨情感,费时费力.机器学习和深度学习技术的发展带来了更为便捷的方法,如高斯混合模型(Gaussian Mixture Mode,GMM)[13,14]、支持向量机(Support Vector Machine,SVM)[15,16]、卷积神经网络(Convolutional Neural Networks,CNN)[17,18]、循环神经网络(Recurrent Neural Network,RNN)[19,20]等都能更方便快速地进行语音情感识别.
本研究探索不同语言在情感识别上的差异性和相似性,在不同语料库进行语音特征提取来进行情感识别的实验.为避免机器学习模型对于情感识别结果的影响,采用SVM,CNN和改进RNN模型三个分类器.通过单语言数据库情感识别、混合语言语料库情感识别、跨语料库情感识别三个实验来对情感识别率进行语言因素的影响,对比分析单语言情感识别、混合语言情感识别和跨语料库情感识别的特点.
1 方 法
1.1 特征提取
语音情感特征是语音情感识别的基础组成部分.本文主要研究基于声学特征的语音情感特征,将语音信号进行数字化.首先需要将音频转化为计算机语言能够识别的数字信号,利用开源工具Opensmile[21]工具包提取eGeMAPS特征集的语音特征,即提取帧水平上的低层次声学特征,包括能量、基频、跨零率、梅尔倒谱系数等常见的帧级特征及其相邻特征的相对变化量.在将语音数据进行归一化的基础上应用不同的统计函数,最终得到88维的声学特征.
1.2 分类器
本实验主要采用SVM,CNN,LSTM(长短时记忆网络,Long⁃Short Term Memory)来进行实验.这三个分类器在语音识别中使用广泛,结果较好.下面详细介绍三个分类器.
SVM能自动寻找出那些对情感分类有较好区分能力的支持向量,构造出的分类器可以最大化类与类的间隔,因而有较好的适应能力和较高的分准率[22].本研究的SVM实验中采用Linear SVC.
CNN通过卷积实现对语音特征局部信息的抽取,再通过聚合加强模型对特征的鲁棒性[17].本研究的实验使用两个卷积层加上两个全连接层,经过softmax激活层后得到四类预测结果.随机打乱数据样本,使用十折交叉方式进行训练与测试.每十个样本计算一次梯度下降,更新一次权重.
RNN可以使信息从当前步传递到下一步,允许信息持久化,但当相关信息和当前预测位置的间隔不断增大时会丧失学习连接如此远的信息的能力.LSTM解决了RNN模型存在的梯度消失的问题,使其能够建模信号的长时依赖关系[23],但由于这种技术的普适性非常高,带来的可能的变化也非常多.本研究的实验主要通过两个LSTM层加上一个全连接层,经过softmax激活层后得到四类预测结果.同样使用十折交叉方式进行训练与测试.每十个样本计算一次梯度下降,更新一次权重.
1.3 实验流程
对语音数据进行归一化处理,以满足不同模式的单语言语料库、混合语言语料库、跨语料库的情感评价的需求.
第一个实验是进行单语言的情感测试,分别放入不同的分类器进行训练和测试,得到该分类器模型下情感的识别率,了解单语言中的情感特点.
第二个实验是进行混合语言语音情感的实验.将不同的语料库进行混合得到新的语料库.不同语言的语料库组合训练可以抑制跨语言效应,增加训练模型的泛化性,其基础是情感的表达和识别具有普遍性,为进一步研究跨语料库的语音情感识别提供实验依据.
第三个实验是进行跨语言的语音情感的实验.利用迁移学习的方法,选择一个语料库进行模型的训练和建立,创建以该语料库为基础的语音情感识别模型,再选取另一个语料库,利用模型迁移的方法对新的语料库情感进行判断.该方法可以很好地体现训练语料库的语音情感表达的特点,测试语料库的测试结果则有利于探究测试语料库和与训练语料库的语音情感的相似性和差异性.
2 实 验
2.1 语料库准备
本文探究中文、英语、德语的语音情感,因此需要选择对应的语料库.下面详细介绍不同的语料库.
IEMOCAP:交互情绪二元动作捕捉数据库(The Interactive Emotional Dyadic Motion Capture database),是由南加利福利亚大学录制的情感数据库,包含视频、音频和语音文本、面部表情四类情感数据[24].由十名专业演员(五男五女)进行情感表达.为了平衡不同情感类别的数据,将快乐和兴奋合并成快乐类别.本实验选取快乐、生气、悲伤和中性四类情感构成最终的语音情感识别数据库,共包含5531句语料.
CASIA:由中国科学院自动化研究所录制的汉语情感语料库[25],共包括四个专业发音人、六种情感(生气、快乐、害怕、悲伤、惊讶和中性).每种情感有50句语料,即对相同的文本赋予不同的情感阅读.
EMO⁃BD:情感语音柏林数据库(The Berlin Database of Emotional Speech),由柏林工业大学传播科学研究所收集[26],被许多研究人员认为是用于语音情感识别分析的标准数据集.由十名演员(五男五女)对十个语句(五长五短)进行七种情感(快乐、生气、焦虑、害怕、无聊、厌恶和中性)的模拟得到,共包含535句语料.语料文本的选取遵从语义中性、无情感倾向的原则,且为日常口语化风格,没有过多的书面语修饰.
上述三个语料库情感的包容性存在差异,因此本研究选择四种共有的情感作为判别情绪,分别为中性、生气、快乐、悲伤.
2.2 单语言情感识别结果
首先在单语言语料库内部进行情感识别,了解不同语料库语言情感识别的特点.识别结果如表1所示.
表1 单语言语料库总体情感识别率
Table 1
| IEMOCAP | CASIA | EMO⁃BD | |
|---|---|---|---|
| Average | 0.563 | 0.59 | 0.756 |
| SVM | 0.58 | 0.74 | 0.76 |
| CNN | 0.55 | 0.52 | 0.69 |
| LSTM | 0.56 | 0.51 | 0.82 |
从总体的准确识别率可以看到,EMO⁃BD的准确率最高,说明德语的情感表达较明显,容易被识别.再看不同的分类器,在IEMOCAP中分类器对结果的影响并不明显,都在0.56左右;对CASIA和EMO⁃BD则存在较为明显的影响.由此可知,分类器对于情感识别的结果的影响是不能忽视的.
在每个语料库内,每种情感的识别率结果如表2所示,表中黑体字表示最高识别率.
表2 单语言语料库单个情感识别率
Table 2
| IEMOCAP | CASIA | EMO⁃BD | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | CNN | LSTM | SVM | CNN | LSTM | SVM | CNN | LSTM | |
| neutral | 0.6 | 0.61 | 0.52 | 0.71 | 0.56 | 0.56 | 0.89 | 0.71 | 0.9 |
| angry | 0.64 | 0.55 | 0.63 | 0.79 | 0.47 | 0.62 | 0.85 | 0.69 | 0.85 |
| happiness | 0.43 | 0.43 | 0.5 | 0.69 | 0.36 | 0.28 | 0.44 | 0.46 | 0.55 |
| sad | 0.69 | 0.64 | 0.67 | 0.79 | 0.65 | 0.59 | 0.94 | 0.95 | 0.98 |
从表2可以看到,不同的情感中悲伤的基本识别率最高(除CASIA在LSTM的训练下,生气的识别率比悲伤高0.03),快乐的识别率在所有实验结果中都最低.说明情感识别确实存在普遍性,悲伤容易识别,而对快乐的识别都存在较大误判.在IEMOCAP和CASIA中,生气的识别准确率仅次于悲伤,在EMO⁃BD中,中性的识别率位于第二.由此可知,情感的识别率与实验的方法存在一定的关系,因此下文的实验依旧保持同时使用三个分类器的方法.
2.3 混合语言情感识别结果
为提高模型的泛化性,对不同的分类器选择两两语料库进行组合训练和三种语料库的全混合实验,具体结果如表3所示,表中黑体字表示最高识别率.
表3 混合语言语料库总体情感识别率
Table 3
| CASIA+IEMOCAP | EMO⁃BD+IEMOCAP | CASIA+EMO⁃BD | CASIA+IEMOCAP+EMO⁃BD | |
|---|---|---|---|---|
| Average | 0.4469 | 0.4001 | 0.4355 | 0.4327 |
| SVM | 0.6719 | 0.7618 | 0.7344 | 0.6956 |
| CNN | 0.3453 | 0.2215 | 0.305 | 0.3146 |
| LSTM | 0.3234 | 0.217 | 0.267 | 0.288 |
首先从识别准确率的结果可以看到,SVM分类器的训练结果最好(0.67~0.76),而其他两个分类器训练的准确率明显低很多,只有0.21~0.35.对EMO⁃BD和IEMOCAP语料库混合之后的语料库的情感识别率较差,但其他三种混合方式的情感识别率都相对较好.
表4 混合语言语料库单个情感识别率
Table 4
| CASIA+IEMOCAP | EMO⁃BD+IEMOCAP | CASIA+EMO⁃BD | CASIA+IEMOCAP+EMO⁃BD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | CNN | LSTM | SVM | CNN | LSTM | SVM | CNN | LSTM | SVM | CNN | LSTM | |
| neutral | 0.62 | 0.41 | 0.36 | 0.77 | 0.34 | 0.43 | 0.79 | 0.31 | 0.25 | 0.67 | 0.32 | 0.25 |
| angry | 0.72 | 0.45 | 0.44 | 0.76 | 0.17 | 0.13 | 0.78 | 0.43 | 0.36 | 0.77 | 0.44 | 0.42 |
| happiness | 0.6 | 0.34 | 0.25 | 0.68 | 0.19 | 0.21 | 0.52 | 0.23 | 0.21 | 0.56 | 0.25 | 0.18 |
| sad | 0.74 | 0.18 | 0.24 | 0.85 | 0.19 | 0.11 | 0.84 | 0.2 | 0.21 | 0.77 | 0.21 | 0.27 |
2.4 跨语言情感识别结果
利用迁移学习进行跨语料库的语音情感识别,测试集和训练集分别来自不同的语料库,了解不同语言语音情感的泛化性和适应性.跨语言情感识别率结果如表5所示,表中黑体字表示跨语料库的语音情感识别率结果高于该语料库内的语音情感识别率.
表5 跨语料库总体情感识别率
Table 5
| 分类器 | 基础语料库 | 迁移语料库 | ||
|---|---|---|---|---|
| IEMOCAP | CASIA | EMO⁃BD | ||
| SVM | IEMOCAP | 0.5802 | 0.495 | 0.4749 |
| CASIA | 0.4321 | 0.7425 | 0.53392 | |
| EMO⁃BD | 0.46103 | 0.49375 | 0.75811 | |
| CNN | IEMOCAP | 0.5466 | 0.51 | 0.59 |
| CASIA | 0.4319 | 0.51875 | 0.46018 | |
| EMO⁃BD | 0.4234 | 0.37875 | 0.6932 | |
| LSTM | IEMOCAP | 0.5637 | 0.4975 | 0.5516 |
| CASIA | 0.4408 | 0.51375 | 0.45723 | |
| EMO⁃BD | 0.4366 | 0.44125 | 0.823 | |
从表5可以看到,以IEMOCAP为基础训练的模型,将别的语料迁移到它上面训练得到的情感识别率最高(0.47~0.59).以EMO⁃BD为基础训练的模型,虽然在以自身为训练集和测试集时有最好的训练结果(0.69~0.82),但是将别的语料库迁移到它上面训练的时候并没有得到较好的结果.对于以CASIA为基础训练的模型进行迁移学习之后发现,EMO⁃BD作为测试集在该模型上进行迁移学习的情感识别率高于IEMOCAP,并且在三个分类器模型上都得到一样的结果.
图1
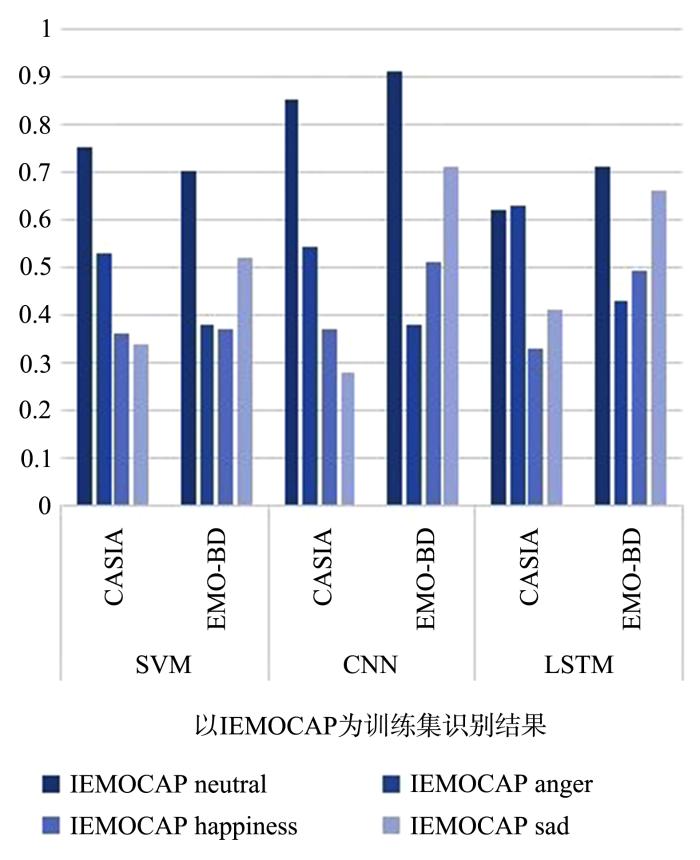
图1
以IEMOCAP为训练模型的跨语料库单个情感识别率
Fig.1
Single emotional recognition rate of cross⁃corpus using IEMOCAP as training mode
图2
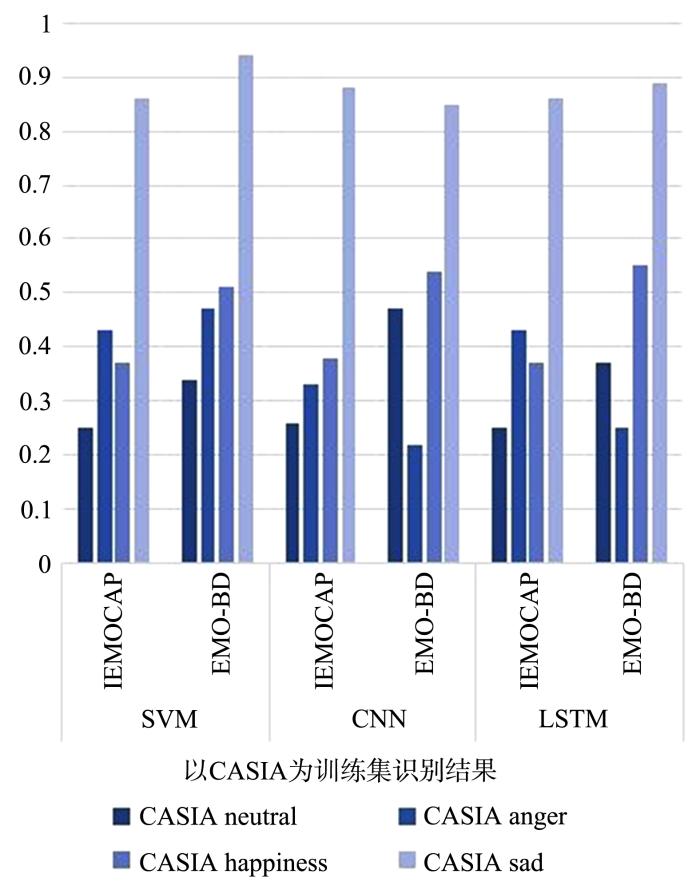
图2
以CASIA为训练模型的跨语料库单个情感识别率
Fig.2
Single emotional recognition rate of cross⁃corpus using CASIA as training model
图3
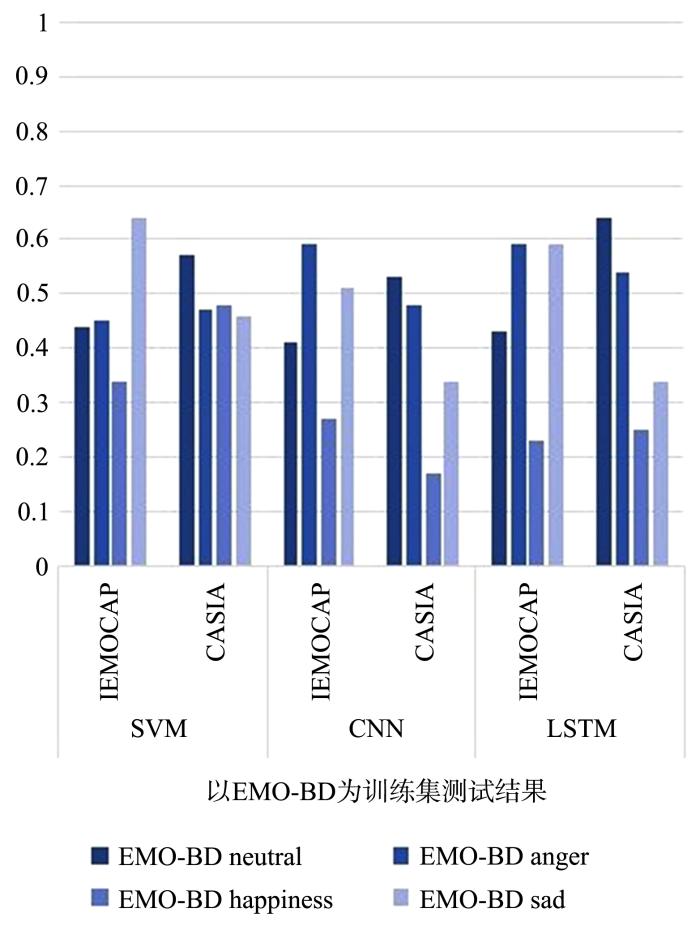
图3
以EMO⁃BD为训练模型的跨语料库单个情感识别率
Fig.3
Single emotional recognition rate of cross⁃corpus using EMO⁃BD as training model
在以IEMOCAP为训练集时,迁移学习情感识别率最高的都是中性的情感(中性识别率0.62~0.91,其他情感的识别率0.28~0.71).在CASIA的测试中,快乐和悲伤的识别率较差,在EMO⁃BD的测试中,生气的识别率最差.所以IEMOCAP的中性情感在三类分类器的训练下有较好的泛化性,但CASIA中的快乐和悲伤以及EMO⁃BD中的生气的适应性较差.在以CASIA为训练集时,单个情感识别率最好的是悲伤(识别率0.85~0.94),中性情感识别率最差(识别率0.25~0.47),所以CASIA的悲伤情感在三类分类器的训练下具有较好的泛化性能,中性情感的泛化性较低.在以EMO⁃BD为训练集时,在CASIA上中性情感的识别率较好(识别率0.53~0.64),在IMEOCAP测试中悲伤和愤怒的识别率较好(识别率0.43~0.59),快乐的识别率最低(0.17~0.34),所以EMO⁃BD情感模型的泛化性存在训练集的差异.
在使用IEMOCAP为测试集时,悲伤的识别率最高(0.59~0.88),说明IEMOCAP的悲伤情感具有良好的适应性.而中性和快乐的适应性最差,中性情感难以适应CASIA模型,快乐情感难以适应EMO⁃BD模型.
在使用CASIA为测试集时,可以发现中性情感的识别率始终最好(0.53~0.85),具有较好的适应性.而快乐和悲伤的识别率较低,说明快乐和悲伤的适应性较差,且使用不同的分类器,测试的结果也会不同.
在EMO⁃BD为测试集时,中性情感能较好地适应IEMOCAP的情感模型(0.7~0.91),悲伤情感能够较好地适应CASIA的情感模型(0.86~0.94).但是对愤怒的识别率和适应性都较差,得不到好的结果.
从上述的实验结果可知,IEMOCAP的中性情感、CASIA的悲伤情感泛化性较好,能较好地识别不同语言的语音情感.IEMOCAP的悲伤情感、CASIA的中性情感有较好的适应性,能很好地适应不同的模型.EMO⁃BD自身的情感识别率较好,但情感泛化性和适应性较差.快乐情感在所有实验中的识别率都较差.
2.5 结果与讨论
从上述三个实验中可以发现,分类器的选择会影响情感识别的结果,不同语言的情感识别率也存在明显差异,其中,EMO⁃BD数据库训练的结果最好,德语的语音情感容易识别,其他的研究者也得到了相似结果[8].在其他情感中,快乐的识别率最差,因为快乐在面部表情中具有更好的处理优势[27],微笑的感知显著性使快乐在面部表情中具有高度的独特性[28],反而在声音特征上没有那么明显.每个语言的悲伤情感的识别结果都是最好的,相关研究也发现许多负面情绪,如愤怒、恐惧和悲伤(即悲伤或绝望)都可以通过声音来最有效地传达.从生理学的角度来看,传达者对这种负面情绪的表达往往是特定的、具有高信号值的信息,但这些信息通常不能建立在联合视觉注意的距离上[29],却在语音上能够被更好地捕捉到.Pell et al[11]发现在声学特征上悲伤的表达具有显著一致性,使得该情感表达稳定且易于识别.这一点在本研究的实验中也得到了证实,悲伤的识别率通常较好.跨语料库的情感识别实验表现了语音情感识别存在的语言依赖性,但直接应用不同语言的情感数据库进行情感识别必然导致较大的误差.
3 总 结
在全球化的影响下,不同语言的交流也日益频繁,语言对于情感识别的影响也不容忽视.本文基于不同的语料库对语音情感的普遍性和差异性进行了探究,进行了单语言、混合语言、跨语言三个实验,比较不同语言下自身语音情感识别率的差异、混合语言情感模型的识别、跨语言的语音情感的泛化性和适应性.实验结果表明,分类器对识别率的影响确实存在;德语数据库的语音情感的识别率最高;简单地混合不同语言不能建立良好的情感模型,利用迁移学习的方法可以找到泛化性较好的情感和适应性较好的情感.未来的工作将进一步探讨在更多数据集上的跨语料库的语音情感的识别结果,得到更多语言情感的相似性和差异性.
参考文献
基于特征迁移学习方法的跨库语音情感识别
Cross⁃corpus speech emotion recognition based on a feature transfer learning method
Within and cross⁃corpus speech emotion recognition using latent topic model⁃based features
Cross⁃corpus acoustic emotion recognition:variances and strategies
Using multiple databases for training in emotion recognition:to unite or to vote?∥Proceedings of the 12th Annual Conference of the International Speech Communication Association
Supervised domain adaptation for emotion recognition from speech∥2015 IEEE International Conference on Acoustics,Speech and Signal Processing
Domain adaptation for speech emotion recognition by sharing priors between related source and target classes∥2016 IEEE International Conference on Acoustics,Speech and Signal Processing
情感表达的跨文化多模态感知研究
Intercultural multimodal perception of emotional expressions
Emotion inferences from vocal expression correlate across languages and cultures
Factors in the recognition of vocally expressed emotions:a comparison of four languages
Cross⁃cultural emotional prosody recognition:evidence from Chinese and British listeners
Cross⁃cultural differences in the processing of non⁃verbal affec⁃tive vocalizations by Japanese and Canadian listeners
Cross⁃cultural recognition of basic emotions through nonverbal emotional vocalizations
Implementation and comparison of speech emotion recognition system using Gaussian Mixture Model (GMM) and K⁃Nearest Neighbor (K⁃NN) techni⁃ques
基于GMM的语音情感信息识别
Emotion recognition of speech based on GMM
Research on text sentiment analysis based on CNNs and SVM∥2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA)
基于多级SVM分类的语音情感识别算法
Speech emotion recognition algorithm based on multi⁃layer SVM classification
Learning deep features to recognise speech emotion using merged deep CNN
基于卷积神经网络学习的语音情感特征降维方法研究
Research on a dimension reduction method of speech emotional feature based on convolution neural network
Long short term memory recurrent neural network based encoding method for emotion recognition in video∥IEEE International Conference on Acoustics,Speech and Signal Processing
基于改进主题分布特征的神经网络语言模型
Neural network language modeling using an improved topic distribution feature
Opensmile:The munich versatile and fast open⁃source audio feature extractor∥Proceedings of the 18th ACM International Conference on Multimedia
.
SVM scheme for speech emotion recognition using MFCC feature
Combining long short⁃term memory and dynamic Bayesian networks for incremental emotion⁃sensitive artificial listening
IEMOCAP:interactive emotional dyadic motion capture database
The CASIA audio emotion recognition method for audio/visual emotion challenge 2011∥Proceedings of the 4th International Conference on Affective Computing and Intelligent Interaction
.
A database of German emotional speech∥Proceedings of Interspeech 2005
Looking for foes and friends:perceptual and emotional factors when finding a face in the crowd
Memory for facial expressions:the power of a smile
The role of culture in emotion⁃antecedent appraisal

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}