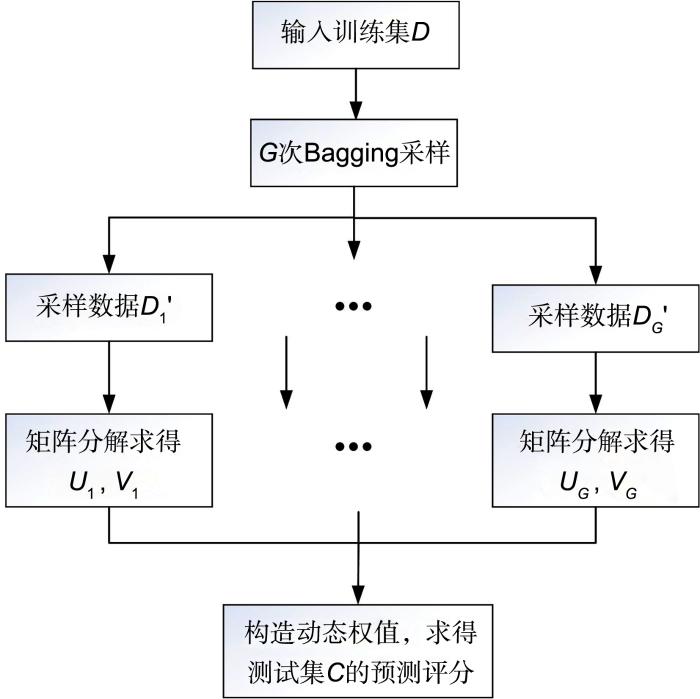
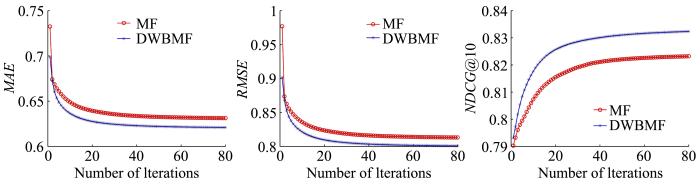
To promote the prediction accuracy of the recommender system,the traditional methods generally use the additional information to construct model,which always increase the time consumption greatly,as well they always needs more detailed data. To solve the problem above,we propose a Bagging⁃based matrix factorization model which assigns dynamic weights to every base learner according to the number of users’ and items’ ratings,then acquires the prediction ratings by weight summation. The experimental results on three real datasets show that our dynamic⁃weighted bagging matrix factorization model has the same efficiency as the traditional matrix factorization model,and it is superior to the traditional matrix factorization on all measures.
Keywords:recommender system
;
matrix factorization
;
Bagging
;
dynamic weighting
He Yifan, Zou Haitao, Yu Hualong. Recommender system model based on dynamic⁃weighted bagging matrix factorization. Journal of nanjing University(Natural Science)[J], 2019, 55(4): 644-650 doi:10.13232/j.cnki.jnju.2019.04.014
推荐算法的主要目的就是从用户和产品的历史数据中分析用户、产品的某些特征,并预测出某用户对产品的喜好程度,再向用户推荐他所可能喜欢的产品.在Shardanand and Maes[1]提出的基于用户相似度的推荐算法中,通过用户评分数据来计算用户间的相似度,选取相似度较大的作为邻居用户,再通过邻居用户对某产品评分的加权求和来得到预测评分.该算法被运用于国外的音乐网站Ringo为用户推荐他可能喜欢的音乐,取得了不错的效果.由于产品数量的爆发式增加,Deshpande and Karypis[2]提出了一种基于产品相似度的推荐算法.该算法首先计算出产品之间的相似度,然后通过用户已购买的产品列表计算出用户对各个产品的喜好程度,在产品数较多的情况下具有优于基于用户相似度推荐算法的算法表现.上述算法都是基于相似度的推荐算法,此类算法在较为稀疏的数据集上无法精准地构造用户或产品间的相似度关系,导致算法预测精度较差.
在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等.
上述模型都以预测评分和真实评分的差的平方为目标函数,通过最优化方法迭代求解用户、产品的隐含特征.Park et al[8]以目标函数的重构为出发点,提出以成对损失替代原始目标函数,最小化用户之间在共同购买产品上预测评分大小关系与真实评分大小关系的差,能获得更好的预测精度,但也带来了更高的时间复杂度.Xu et al[9]构造了一种不断缩小预测方差的高阶评分距离模型.在构造目标函数时,高阶评分距离模型不仅考虑用户对产品的预测评分与实际评分间的差异(称为一阶评分距离),还增加了同一用户对不同产品的预测评分与实际评分差异的差异(称为二阶评分距离).二阶评分距离的引入能不断缩小预测结果的方差,提高预测的精度,但由于模型过于复杂,算法的时间复杂度随数据集规模的增长呈指数增长.
集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足.
对于矩阵分解模型,实验中使用Xu et al[9]的参数,学习率.实验证明,Bagging集成表现随的增大而趋于稳定.基于时间效率的考量,实验中将设置为4.这样,当实验在四核CPU上并行时,只有和单个矩阵分解一样的时间消耗.此外,实验总迭代次数设置为80次,这个迭代次数已经可以保证算法收敛.前期实验表明,算法的预测精度会随着用户、产品特征矩阵维度的增长而提高,但在维度超过45时这种提高几乎消失,所以本文所有算法的特征矩阵维度都设置为45.
HoORaYs:high⁃order optimization of rating distance for recom⁃mender systems∥Proceedings of the 23th International Conference on Knowledge Discoveryand Data Mining.
Social information filtering:algorithms for automating “Word of Mouth”∥Proceedings of the SIGCHI Conference on Human Factors in Computing Systems
1
1995
... 推荐算法的主要目的就是从用户和产品的历史数据中分析用户、产品的某些特征,并预测出某用户对产品的喜好程度,再向用户推荐他所可能喜欢的产品.在Shardanand and Maes[1]提出的基于用户相似度的推荐算法中,通过用户评分数据来计算用户间的相似度,选取相似度较大的作为邻居用户,再通过邻居用户对某产品评分的加权求和来得到预测评分.该算法被运用于国外的音乐网站Ringo为用户推荐他可能喜欢的音乐,取得了不错的效果.由于产品数量的爆发式增加,Deshpande and Karypis[2]提出了一种基于产品相似度的推荐算法.该算法首先计算出产品之间的相似度,然后通过用户已购买的产品列表计算出用户对各个产品的喜好程度,在产品数较多的情况下具有优于基于用户相似度推荐算法的算法表现.上述算法都是基于相似度的推荐算法,此类算法在较为稀疏的数据集上无法精准地构造用户或产品间的相似度关系,导致算法预测精度较差. ...
Item?Based Top?N recommendation algorithms
1
2004
... 推荐算法的主要目的就是从用户和产品的历史数据中分析用户、产品的某些特征,并预测出某用户对产品的喜好程度,再向用户推荐他所可能喜欢的产品.在Shardanand and Maes[1]提出的基于用户相似度的推荐算法中,通过用户评分数据来计算用户间的相似度,选取相似度较大的作为邻居用户,再通过邻居用户对某产品评分的加权求和来得到预测评分.该算法被运用于国外的音乐网站Ringo为用户推荐他可能喜欢的音乐,取得了不错的效果.由于产品数量的爆发式增加,Deshpande and Karypis[2]提出了一种基于产品相似度的推荐算法.该算法首先计算出产品之间的相似度,然后通过用户已购买的产品列表计算出用户对各个产品的喜好程度,在产品数较多的情况下具有优于基于用户相似度推荐算法的算法表现.上述算法都是基于相似度的推荐算法,此类算法在较为稀疏的数据集上无法精准地构造用户或产品间的相似度关系,导致算法预测精度较差. ...
Fast maximum margin matrix factorization for collaborative prediction∥Proceedings of The 22th International conference on Machine learning
1
2005
... 在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等. ...
Probabilistic matrix factorization∥Proceedings of the 20th International Conference on Neural Information Processing Systems
1
2008
... 在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等. ...
Matrix factorization techniques for recommender systems
1
2009
... 在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等. ...
Adaptive ensemble with trust networks and collaborative recommendations
1
2015
... 在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等. ...
Aspect?aware latent factor model: Rating prediction with ratings and reviews
1
2018
... 在解决上述问题的过程中,矩阵分解模型[3]进入了研究者的视线.研究者们发现在隐含特征空间中某用户对产品的偏好(评分)可以根据用户特定的系数对产品特征向量进行线性组合得到.Salakhutdinov and Mnih[4]对矩阵分解模型给出了概率层次的解释,并提出一种受限概率矩阵分解模型(Constraint⁃Probabilistic Matrix Factorization),在构造用户特征矩阵时加入代表用户之间关系的隐含特征矩阵,大大提高了对稀疏、不平衡数据的预测精度.Koren et al[5]提出矩阵分解算法的几个变种,向原始矩阵分解模型中加入偏好、置信度等概念,提升算法的预测精度.此外,还有不少学者利用其他外部信息与矩阵分解模型构成混合模型,针对特定的数据集获得精准的推荐.如Zou et al[6]利用社交网络中社区成员之间的信任度作为用户间的相似度协同产生预测评分,Cheng et al[7]通过用户评分与评论共同协作产生推荐等. ...
Preference completion:large?scale collaborative ranking from pairwise comparisons∥Proceedings of the 32th International Conference on Machine Learning
1
2015
... 上述模型都以预测评分和真实评分的差的平方为目标函数,通过最优化方法迭代求解用户、产品的隐含特征.Park et al[8]以目标函数的重构为出发点,提出以成对损失替代原始目标函数,最小化用户之间在共同购买产品上预测评分大小关系与真实评分大小关系的差,能获得更好的预测精度,但也带来了更高的时间复杂度.Xu et al[9]构造了一种不断缩小预测方差的高阶评分距离模型.在构造目标函数时,高阶评分距离模型不仅考虑用户对产品的预测评分与实际评分间的差异(称为一阶评分距离),还增加了同一用户对不同产品的预测评分与实际评分差异的差异(称为二阶评分距离).二阶评分距离的引入能不断缩小预测结果的方差,提高预测的精度,但由于模型过于复杂,算法的时间复杂度随数据集规模的增长呈指数增长. ...
HoORaYs:high?order optimization of rating distance for recom?mender systems∥Proceedings of the 23th International Conference on Knowledge Discoveryand Data Mining.
2
2017
... 上述模型都以预测评分和真实评分的差的平方为目标函数,通过最优化方法迭代求解用户、产品的隐含特征.Park et al[8]以目标函数的重构为出发点,提出以成对损失替代原始目标函数,最小化用户之间在共同购买产品上预测评分大小关系与真实评分大小关系的差,能获得更好的预测精度,但也带来了更高的时间复杂度.Xu et al[9]构造了一种不断缩小预测方差的高阶评分距离模型.在构造目标函数时,高阶评分距离模型不仅考虑用户对产品的预测评分与实际评分间的差异(称为一阶评分距离),还增加了同一用户对不同产品的预测评分与实际评分差异的差异(称为二阶评分距离).二阶评分距离的引入能不断缩小预测结果的方差,提高预测的精度,但由于模型过于复杂,算法的时间复杂度随数据集规模的增长呈指数增长. ...
... 对于矩阵分解模型,实验中使用Xu et al[9]的参数,学习率.实验证明,Bagging集成表现随的增大而趋于稳定.基于时间效率的考量,实验中将设置为4.这样,当实验在四核CPU上并行时,只有和单个矩阵分解一样的时间消耗.此外,实验总迭代次数设置为80次,这个迭代次数已经可以保证算法收敛.前期实验表明,算法的预测精度会随着用户、产品特征矩阵维度的增长而提高,但在维度超过45时这种提高几乎消失,所以本文所有算法的特征矩阵维度都设置为45. ...
Resampling?based ensemble methods for online class imbalance learning
1
2015
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...
A novel ensemble method for classifying imbalanced data
2
2015
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...
基于集成学习的个性化推荐算法
1
2011
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...
融合协同过滤和XGBoost的推荐算法
1
2018
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...
融合协同过滤和XGBoost的推荐算法
1
2018
... 集成学习[10,11]的方法也被运用于提高推荐算法的精度.Sun et al[11]通过线性回归对多个算法分配权值,最终把各个算法的预测评分加权求和作为预测评分.方育柯等[12]集成基于用户相似度的推荐算法,使用不同的相似度度量产生不同的推荐模型,并加权求和得到最终的预测评分,提高了模型的预测精度.崔岩等[13]结合基于用户和基于产品的预测评分差与真实评分构造出新的数据集,再通过XGboost模型进行训练与预测.上述的集成方法,都以基于内容的推荐算法为基础,该算法本身就存在时间复杂度高、预测精度较低的缺点.此类算法用来计算相似度的时间与用户、产品个数的平方成正比,而且在面临稀疏数据时,甚至会出现相似度均为0的用户或产品,导致此类算法在预测精度方面也有不足. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}