Superheat is an important parameter in the process of aluminum electrolysis. Keeping the superheat within an appropriate range can improve the current efficiency and reduce cell loss. However,the measurement of superheat is difficult and the measurement process is complex. According to granular computing theory,this paper proposes a prediction model of superheat based on time granule. By constructing time granules on time series,new feature sets and sample sets are constructed combinating with time granules. On this basis,new sample sets are trained by the classifier to obtain the model. In this paper,we use the data of aluminum electrolysis production from Shandong Weiqiao Aluminum and Electricity Ltd to test the experiment. The result shows that the supreheat prediction of this method is better than the existing models.
Keywords:superheat
;
granular computing
;
time series
;
aluminum electrolysis
Guo Yingjie, Hu Feng, Yu Hong, Zhang Hongliang. Prediction model of superheat in aluminum electrolysis based on time granularity. Journal of nanjing University(Natural Science)[J], 2019, 55(4): 624-632 doi:10.13232/j.cnki.jnju.2019.04.012
Series Data Mining,TSDM)研究,目标是从这些“形状”序列数据中挖掘出和时间相关的有价值的知识和信息,或发现有规律的变化模式和异常点等,用于指导和改善日常的生产生活[5].
时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测,
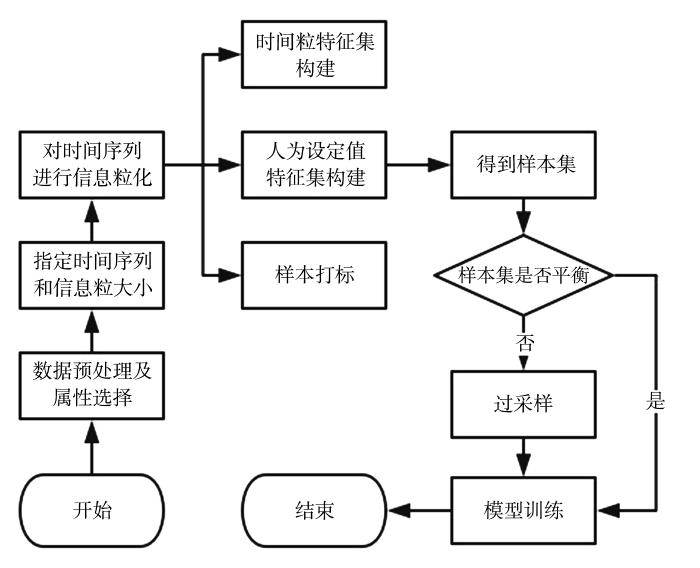
为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较.
Soft measuring model of superheat degree in the aluminum electrolysis production
Chinese association of automation,Ji'nan Muni⁃cipal People's Government∥2017 Chinese Automation Congress(CAC2017) and Intelligent Manufacturing International Conference(CIMIC2017) Proceeding.Chinese Association of Automation,Ji'nan Municipal People's Govern⁃ment:Chinese Association of Automation,2017:161-167.
Prediction of aluminum electrolysis superheat based on relative density noise filtering random forest
Chinese Association of Automation,Ji'nan Municipal People's Government∥2017 Chinese Automation Congress (CAC2017) & Intelligent Manufacturing Interna⁃tional Conference (CIMIC2017) Proceeding.Chinese Association of Automation,Ji'nan Municipal People's Government:Chinese Association of Automation,2017, 324-329).
A time⁃dependent enhanced support vector machine for time series regression∥Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
时间序列的多粒度智能分析方法研究
1
2017
... Series Data Mining,TSDM)研究,目标是从这些“形状”序列数据中挖掘出和时间相关的有价值的知识和信息,或发现有规律的变化模式和异常点等,用于指导和改善日常的生产生活[5]. ...
时间序列的多粒度智能分析方法研究
1
2017
... Series Data Mining,TSDM)研究,目标是从这些“形状”序列数据中挖掘出和时间相关的有价值的知识和信息,或发现有规律的变化模式和异常点等,用于指导和改善日常的生产生活[5]. ...
Time series analysis: forecasting and control
1
2010
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
Toward automatic time?series fore?casting using neural networks
1
2012
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
Competition and collaboration in cooperative coevolution of elman recurrent neural networks for time?series prediction
1
2015
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
Developing a local least?squares support vector machines?based neuro?fuzzy model for nonlinear and chaotic time series 0prediction
1
2013
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
A weighted LS?SVM based learning system for time series forecasting
1
2015
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
A time?dependent enhanced support vector machine for time series regression∥Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
1
2013
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
Maximum and minimum stock price forecasting of Brazilian power distribution companies based on artificial neural networks
1
2015
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
Introduction to interval analysis
1
2009
... 时间序列预测是传统时间序列分析的基本目标,也是TSDM的主要挖掘任务之一.它通过已知的时间序列的历史观测值去预测未来某一时刻或者某一时段的值,通常指下一时刻.传统时间序列预测模型主要是基于概率统计学的建模方法,最典型的代表是Box and Jenkins[6]提出的差分整合移动平均自回归模型(Autoregressive Integrated Moving Average Model,ARIMA)系列(主要包括自回归模型(Autoregressive Model,AR),滑动平均模型(Moving Average Model,MA),自回归滑动平均模型(Auto⁃Regressive Moving Average Model,ARMA)和ARIMA).随着人工智能技术的飞速发展,一些经典机器学习方法如神经网络(Artificial Neural Network,ANN)[7,8,9]和支持向量回归机(Support Vactor Regerssion,SVR)[10,11,12]已广泛应用于时间序列预测.例如,Moore et al[13]利用径向神经网络对水质时间序列进行预测, ...
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
Cluster?based under?sampling approaches for imbalanced data distributions
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
Predicting kidney transplantation outcome based on hybrid feature selection and KNN classifier
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...
Network intrusion detection system using J48 Decision Tree∥International Conference on Advances in Computing,Communications and Informatics
... 为考察文中提出的基于时间粒的过热度预测模型的性能,本文将其与杨吉森提出的过热度软测量模型(Soft Measuring Model of Superheat Degree,SMM)[3]和刘运胜提出的基于相对密度噪声过滤随机森林的铝电解过热度模型(Prediction of Aluminum Electrolysis Superheat Based on Relative Density Noise Filtering Random Forest,RDNF⁃RF)[4]进行对比.采用文中提出的PMBTG算法,使用sklearn中的XGBoost[20]分类器和weka平台下的RandomForest[21],IBK[22]和J48[23]分类器分别对样本集进行训练(模型记作PMBTG⁃XGB,PMBTG⁃RF,PMBTG⁃IBK和PMBTG⁃J48),将训练得到的模型与SMM和RDNF⁃RF模型进行比较. ...



{kind=link}
{kind=link}