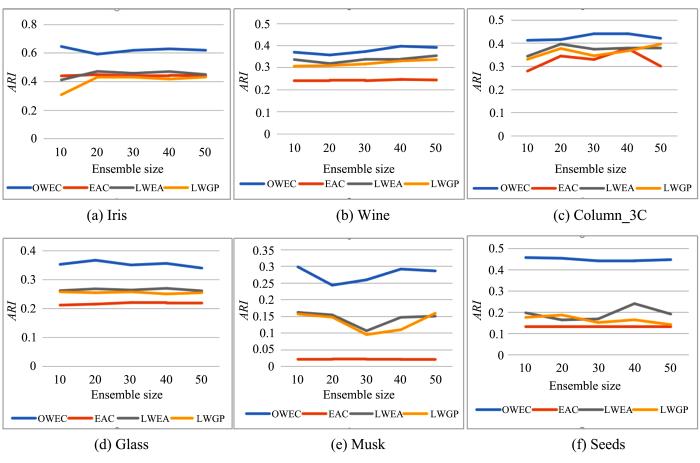
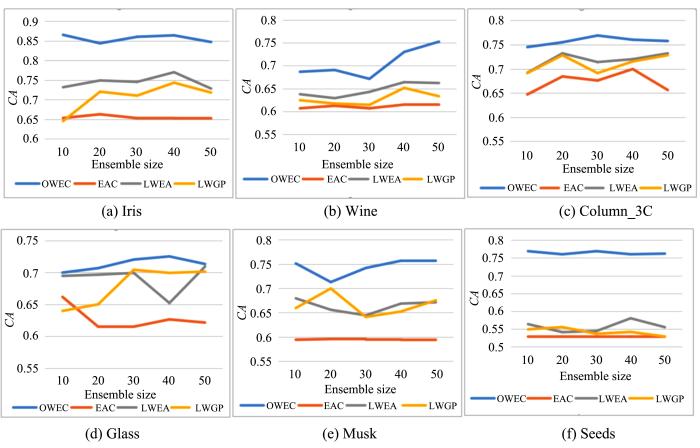
The goal of clustering ensemble is to improve the stability,robustness and accuracy of the final clustering results by integrating multiple clustering results. In recent years,clustering ensemble has attracted more and more attention. One limitation of most existing clustering ensemble methods is that they generally treat all base clustering equally,regardless of their importance. Although scholars have made some efforts in this aspect,for example,the weighted strategy is used to improve the co⁃association matrix. However,they ignore the difference in the contribution of samples to the classes they belong to when either weighting the base clustering or evaluating the class importance. Therefore,sample pairwise weighting co⁃association matrix based ensemble clustering algorithm is proposed. The algorithm firstly uses the k⁃means algorithm to generate multiple base partition results and multiple small classes for each class. The importance of the sample to the class is evaluated by calculating the change degree of uncertainty of the class after removing the subclass of the sample pairwise. Finally,the final clustering result can be obtained through the hierarchical clustering algorithm. Experimental results on six UCI data sets show that the performance of sample pairwise weighting co⁃association matrix based clustering ensemble algorithm is superior to the three classical clustering ensemble algorithms based on co⁃association matrix.
集成聚类算法中通过对基聚类进行加权可以更好地平衡各基聚类对最终聚类结果的贡献,得到性能更好的集成聚类算法,再通过一致性函数来得到最后的划分.最常用的方法有k⁃means[1],PAM(Partitioning Around Medoid)[11]以及层次聚类的单连接、平均连接等方法.对于共协关系矩阵来说,任何一种聚类算法都可用于产生最终的聚类结果.
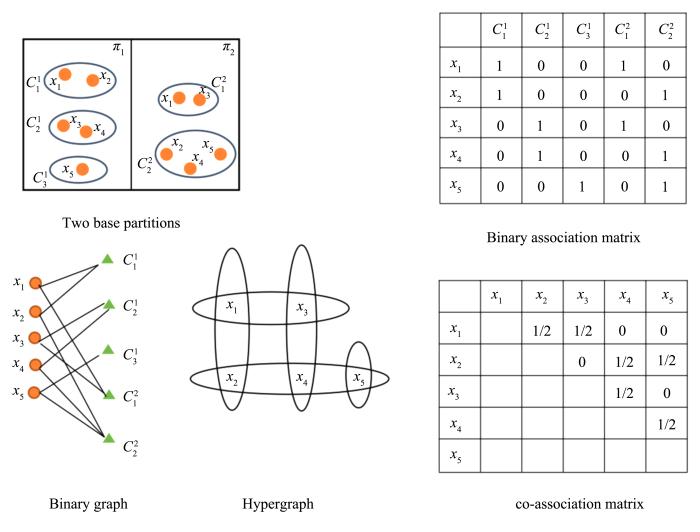
在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度.
Soundness and separability of workflow nets in the stepwise refinement approach∥Proceedings of the 24th International Conference on Application and Theory of Petri Nets
... 集成聚类算法中通过对基聚类进行加权可以更好地平衡各基聚类对最终聚类结果的贡献,得到性能更好的集成聚类算法,再通过一致性函数来得到最后的划分.最常用的方法有k⁃means[1],PAM(Partitioning Around Medoid)[11]以及层次聚类的单连接、平均连接等方法.对于共协关系矩阵来说,任何一种聚类算法都可用于产生最终的聚类结果. ...
Soundness and separability of workflow nets in the stepwise refinement approach∥Proceedings of the 24th International Conference on Application and Theory of Petri Nets
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
... [8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
Finding groups in data:an introduction to cluster analysis
1
1990
... 集成聚类算法中通过对基聚类进行加权可以更好地平衡各基聚类对最终聚类结果的贡献,得到性能更好的集成聚类算法,再通过一致性函数来得到最后的划分.最常用的方法有k⁃means[1],PAM(Partitioning Around Medoid)[11]以及层次聚类的单连接、平均连接等方法.对于共协关系矩阵来说,任何一种聚类算法都可用于产生最终的聚类结果. ...
Temporal data clustering via weighted clustering ensemble with different representations
2
2010
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
... [12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
Weighted co?clustering based clustering ensemble∥3rd National Conference on Computer Vision,Pattern Recognition,Image Processing and Graphics
2
2011
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
... [13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
A clustering ensemble:Two?level?refined co?association matrix with path?based transformation
2
2015
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
... [14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
Locally weighted ensemble clustering
7
2018
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
基于决策加权的聚类集成算法
1
2016
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
Ensemble clustering based on weighted co?association matrices:error bound and convergence properties
1
2017
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
A comprehensive study of clustering ensemble weighting based on cluster quality and diversity
1
2019
... 在过去的几年中,学者们提出许多聚类集成的方法[8,12,13,14,15,16,17,18].Fred and Jain[8]提出Evidence Accumulation Clustering(EAC)算法,构建共协关系矩阵,若一对样本出现在一个类中,值为1,否则为0,最后通过层次聚类的方法得到最后的聚类结果.这一方法平等地对待基聚类、类以及样本,但忽略了它们不同的贡献.许多学者为了改善这一情况,通过改进共协关系矩阵从而更大程度地利用聚类结果所给的信息,得到最后的聚类结果.其中,有通过评价基聚类的重要度来改进共协关系矩阵的一些方法,Yang and Chen[12]通过融合三个不同的评价聚类的指标来给基聚类一个权值,从而得到加权的共协关系矩阵.Nanda and Pujari[13]也提出了一个加权聚类集成的方法,通过计算样本和类中心的距离与类中心之间的距离的差值来评价一个基聚类的重要度,给基聚类一个权值,从而得到加权的共协关系矩阵.这一类方法造成在一个划分中所有被分到同一个类中样本对的值都是相同的结果,忽略了类与样本对于基聚类的贡献.为了改善这一问题,学者们又提出通过评价类的重要度来改进共协关系矩阵的一些方法.Zhong et al[14]通过计算样本之间的距离来评价一个类的可靠度.Huang et al[15]用熵来评价一个类的不确定程度从而得到类的重要度来给每对样本一个权值,但这样会使出现在同一个类中的所有样本给定的权值都是一样,也就是说在同一个类中的每个样本都被平等对待,显然,这样不能精准评价样本的贡献程度. ...
Objective criteria for the evaluation of clustering methods




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}