Network embedding,or network representation learning,aims to map nodes in the network into the representation space and generate low⁃dimensional dense vectors to represent the nodes in the network while preserving the network structure information,then solve downstream tasks such as link prediction,node classification,community discovery and network visualization through existing machine learning methods. The random walk algorithm can well explore the structure of nodes in the network. However,the previous representation learning algorithm based on random walk can only generate one kind of embedding for one node,without considering that the nodes play different roles when interacting with different neighbors. Therefore,this paper proposes a network embedding algorithm based on mutual attention of paths. Through the context information generated by random walks of nodes,each node generates a node embedding in which contexts are of mutual attention. And our algorithm has better performance than the three classic network embedding algorithms.
Keywords:network representation learning
;
random walk
;
mutual attention
;
attention mechanism
早期的网络表示学习大部分是基于矩阵分解思想,矩阵分解算法主要通过表示网络中节点的连接关系,然后对矩阵进行分解从而获得节点的向量表示.最早基于矩阵分解的网络表示学习算法LLE(Locally Linear Embedding)由Roweis and Saul[9]提出,认为在向量空间中的节点表示应该是该节点所有邻居节点的线性组合,并且权重由节点的邻接矩阵所确定.
Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能.
随着卷积神经网络(Convolutional Neural Networks,CNN)的提出以及数值计算设备的不断改进,越来越多的算法效果通过运用CNN得到了提升,特别是在图像领域和自然语言处理领域.Kalchbrenner et al[16]提出采用卷积神经网络用于句子建模.同年,Hu et al[17]提出了用于匹配自然语言句子的卷积神经网络体系结构.2016年Attentive Pooling Networks[18]被提出用于问答系统,取得了很好的效果.Tu et al[6]于2017年提出的CANE(Context⁃Aware Network Embedding)认为在真实世界中一个节点可能在和不同的节点交互时表现出不同的特性,从而利用节点的文本信息进行相互关注的网络表示学习,并采用Attentive Pooling模型,取得了较好的效果.但是CANE只能应用于具有有效文本信息的网络.
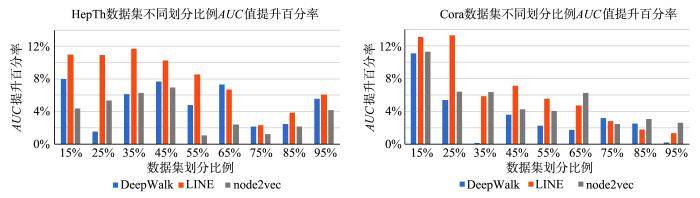
链路预测的目标是预测网络中没有出现的边或将来可能出现的边.对于链路预测任务采用标准的衡量指标AUC(Area Under a receiver operating characteristic (roc) Curve),它表示随机未被观测链路中的顶点比随机不存在的链路中的顶点对更相似的概率.在网络嵌入中,一般采用一对顶点的表示向量的余弦相似度或者向量内积来计算得分,本文中采用向量内积来计算得分,AUC的值大于50%的程度越高,表示算法的性能越好.将划分比例r从15%调整到95%进行计算.由于r=5%时,训练集中大多数的点都是孤立的,所以没有进行5%训练集下的实验.按照不同比例分别随机去除Cora,HepTh和NetScience中的边作为测试集,保留的边作为训练集进行训练,其预测结果计算AUC值分别如表2、表3和表4所示,表中黑体字是表现最优的结果.
Laplacian eigenmaps and spectral techniques for embedding and clustering∥Proceedings of the 14th International Conference on Neural Information Processing Systems
Distributed representations of words and phrases and their compositionality∥Proceedings of the 26th International Conference on Neural Information Processing Systems
Convolutional neural network architectures for matching natural language sentences∥Proceedings of the 27th International Conference on Neural Information Processing Systems
Graphs over time:densification laws,shrinking diameters and possible explanations∥Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining
Nonlinear dimensionality reduction by locally linear embedding
1
2000
... 早期的网络表示学习大部分是基于矩阵分解思想,矩阵分解算法主要通过表示网络中节点的连接关系,然后对矩阵进行分解从而获得节点的向量表示.最早基于矩阵分解的网络表示学习算法LLE(Locally Linear Embedding)由Roweis and Saul[9]提出,认为在向量空间中的节点表示应该是该节点所有邻居节点的线性组合,并且权重由节点的邻接矩阵所确定. ...
Laplacian eigenmaps and spectral techniques for embedding and clustering∥Proceedings of the 14th International Conference on Neural Information Processing Systems
1
2001
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
Structural deep network embedding∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
1
2016
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
Distributed representations of words and phrases and their compositionality∥Proceedings of the 26th International Conference on Neural Information Processing Systems
1
2013
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
Deepwalk:online learning of social representations∥Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
1
2014
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
Line:large?scale information network embedding∥Proceedings of the 24th International Conference on World Wide Web
1
2015
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
node2vec:scalable feature learning for networks∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
1
2016
... Laplace特征表示[10]则认为如果两个节点相连,那么它们的表示应该接近,并且这种接近程度是用欧式距离来衡量的.SDNE(Structural Deep Network Embedding)[11]通过深层神经网络对节点进行表示学习,首先使用Laplace矩阵进行第一级相似度的建模,而后使用深层自编码器建模二级相似度.随着自然语言处理技术的发展,Mikolov et al[12]于2013年提出了word2vec模型,这是一种用于学习词表示的神经网络模型,并取得了良好的效果.Perozzi et al[13]观测到节点在短随机游走中的分布和词语在自然语言中的分布都满足幂律分布,从而将word2vec模型引入网络表示学习,提出Deepwalk算法,使得效果有了较大的提升.Tang et al[14]随后又提出LINE(Large⁃scale Information Network Embedding)算法,使用简单的神经网络学习网络表示,通过一阶邻近和二阶邻近来刻画节点之间的关系.其中直接相连的一对节点表示这对节点有着一阶邻近关系,不相邻的一对节点的共同邻居刻画了这对节点的二阶邻近关系.Grover and Leskovec[15]于2016年提出了改进DeepWalk的算法node2vec,通过引入参数p和q调节随机游走的深度和广度的偏好关系提升了算法的性能. ...
A convolutional neural network for modelling sentences
1
2014
... 随着卷积神经网络(Convolutional Neural Networks,CNN)的提出以及数值计算设备的不断改进,越来越多的算法效果通过运用CNN得到了提升,特别是在图像领域和自然语言处理领域.Kalchbrenner et al[16]提出采用卷积神经网络用于句子建模.同年,Hu et al[17]提出了用于匹配自然语言句子的卷积神经网络体系结构.2016年Attentive Pooling Networks[18]被提出用于问答系统,取得了很好的效果.Tu et al[6]于2017年提出的CANE(Context⁃Aware Network Embedding)认为在真实世界中一个节点可能在和不同的节点交互时表现出不同的特性,从而利用节点的文本信息进行相互关注的网络表示学习,并采用Attentive Pooling模型,取得了较好的效果.但是CANE只能应用于具有有效文本信息的网络. ...
Convolutional neural network architectures for matching natural language sentences∥Proceedings of the 27th International Conference on Neural Information Processing Systems
1
2014
... 随着卷积神经网络(Convolutional Neural Networks,CNN)的提出以及数值计算设备的不断改进,越来越多的算法效果通过运用CNN得到了提升,特别是在图像领域和自然语言处理领域.Kalchbrenner et al[16]提出采用卷积神经网络用于句子建模.同年,Hu et al[17]提出了用于匹配自然语言句子的卷积神经网络体系结构.2016年Attentive Pooling Networks[18]被提出用于问答系统,取得了很好的效果.Tu et al[6]于2017年提出的CANE(Context⁃Aware Network Embedding)认为在真实世界中一个节点可能在和不同的节点交互时表现出不同的特性,从而利用节点的文本信息进行相互关注的网络表示学习,并采用Attentive Pooling模型,取得了较好的效果.但是CANE只能应用于具有有效文本信息的网络. ...
Attentive pooling networks
1
2016
... 随着卷积神经网络(Convolutional Neural Networks,CNN)的提出以及数值计算设备的不断改进,越来越多的算法效果通过运用CNN得到了提升,特别是在图像领域和自然语言处理领域.Kalchbrenner et al[16]提出采用卷积神经网络用于句子建模.同年,Hu et al[17]提出了用于匹配自然语言句子的卷积神经网络体系结构.2016年Attentive Pooling Networks[18]被提出用于问答系统,取得了很好的效果.Tu et al[6]于2017年提出的CANE(Context⁃Aware Network Embedding)认为在真实世界中一个节点可能在和不同的节点交互时表现出不同的特性,从而利用节点的文本信息进行相互关注的网络表示学习,并采用Attentive Pooling模型,取得了较好的效果.但是CANE只能应用于具有有效文本信息的网络. ...
Automating the construction of internet portals with machine learning
1
2000
... Cora是一个典型的引文网络数据集,由McCallum et al[20]构建,其中含有2277篇机器学习论文,分为七类,为有向图. ...
Graphs over time:densification laws,shrinking diameters and possible explanations∥Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining
1
2005
... HepTh(高能物理理论)是由Leskovec et al[21]构建的引文网络数据集,保留1038篇论文,为有向图. ...
Finding community structure in networks using the eigenvectors of matrices



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}