 PDF(939 KB)
PDF(939 KB)

Emotion recognition based on visual and auditory information
Xijian Fan, Xubing Yang, Li Zhang, Qiaolin Ye, Ning Ye
Journal of Nanjing University(Natural Sciences) ›› 2021, Vol. 57 ›› Issue (2) : 309-317.
PDF(939 KB)
 PDF(939 KB)
PDF(939 KB)
Emotion recognition based on visual and auditory information
 ({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}
({{custom_author.role_en}}), {{javascript:window.custom_author_en_index++;}}Speech signals and facial expressions are the two main ways when people express their emotions. They are also considered to be the two main modals of emotional expression,i.e.,auditory modality and visual modality. Most of the current methods of emotion recognition research rely on the use of single⁃modal information,but single modal based methods have the disadvantages of incomplete information and vulnerability to noise interference. To address the problems of emotion recognition based on single modal,this paper proposes a bi⁃modal based emotion recognition method that combines auditory modality and visual modal information. Firstly,the Convolutional Neural Network and the pre⁃trained facial expression model are used respectively. The corresponding sound features and visual features are extracted from the speech signal and the visual signal. The extracted two types of features are information fusion and compression,and the relevant information between the modes is fully mined. Finally,the recurrent neural network is used to recognize emotion recognition on the fused auditory visual bimodal features. The method can effectively capture the intrinsic association information between the auditory modality and the visual modality,thereby improve the emotion recognition performance. In this paper,the proposed bimodal identification method is validated by RECOLA dataset. The experimental results show that the model recognition effect based on bimodal is better than a single image or voice recognition model.
affective recognition / feature fusion / Convolutional Neural Network / Long Shot⁃Term Memory {{custom_keyword}} /
Table 1 Recognition of arousal and valence by the visual networks on RECOLA dataset表1 视觉特征提取模型在RECOLA数据集上的Arousal和Valence识别结果 |
| 模型 | 视觉特征 | Arousal | Valence |
|---|---|---|---|
| 本文方法 | 原图像 | 0.493 (0.425) | 0.722 (0.678) |
| Baseline[31] | 纹理特征 | 0.343 (0.483) | 0.486 (0.474) |
| Baseline[31] | 几何特征 | 0.272 (0.379) | 0.507 (0.612) |
| RVM[32] | 纹理特征 | - (0.615) | - (0.530) |
| RVM[32] | 几何特征 | - (0.467) | - (0.571) |
| Weber et al[33] | 纹理特征 | - (0.594) | - (0.506) |
| Weber et al[33] | 几何特征 | - (0.476) | - (0.683) |
| Han et al[34] | 纹理+几何 | 0.265 (0.292) | 0.394 (0.592) |
| Tzirakis et al[13] | 原图像 | 0.435 (0.371) | 0.620 (0.637) |
Table 2 Recognition of arousal and valence by the speech networks on RECOLA dataset表2 听觉特征提取模型在RECOLA数据集上的Arou⁃sal和Valence识别结果 |
| 模型 | 听觉特征 | Arousal | Valence |
|---|---|---|---|
| 本文方法 | 原信号 | 0.720 (0.763) | 0.376 (0.430) |
| Baseline[31] | eGeMAPS | 0.648 (0.796) | 0.375 (0.455) |
| RVM[33] | eGeMAPS | - (0.750) | - (0.396) |
| Brady et al[35] | MFCC | - (0.846) | - (0.450) |
| Weber et al[33] | eGeMAPS | - (0.793) | - (0.456) |
| Han et al[34] | 13 LLDs | -0.666 (0.755) | 0.364 (0.476) |
| Tzirakis et al[13] | 原信号 | 0.715 (0.786) | 0.369 (0.428) |
Table 3 Recognition of arousal and valence by the bimodal networks on RECOLA dataset表3 视觉听觉融合模型在RECOLA数据集上的Arousal和Valence识别结果 |
| 模型 | 听觉特征 | 视觉特征 | Arousal | Valence |
|---|---|---|---|---|
| 本文模型 | 原信号 | 原图像 | 0.801 (0.775) | 0.743 (0.721) |
| OARVM⁃SR[36] | eGeMAPS | 几何 | 0.770 (0.855) | 0.545 (0.642) |
| 强度模型[34] | ComParE | 纹理 | 0.610 (0.728) | 0.463 (0.544) |
| CNN⁃LSTM 混合[13] | 原信号 | 原图像 | 0.789 (0.731) | 0.691 (0.502) |
| 1 |
彭先霖,张海曦,胡琦瑶. 基于多任务深度卷积神经网络的人脸/面瘫表情识别方法. 西北大学学报(自然科学版),2019,49(2):187-192.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
黄程韦,赵艳,金赟 等. 实用语音情感的特征分析与识别的研究. 电子与信息学报,2011,33(1):112-116.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
陈闯,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(939 KB)
PDF(939 KB)
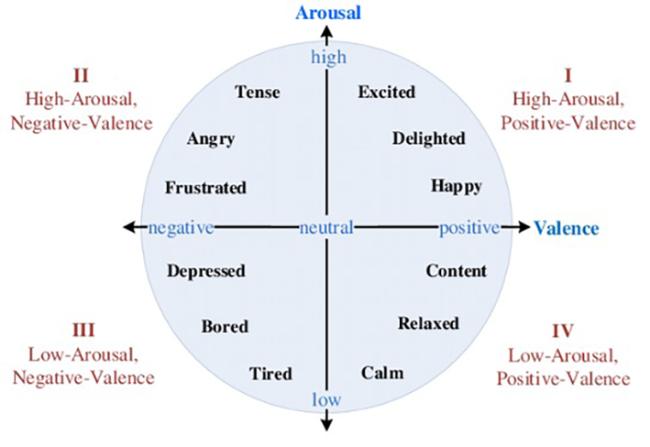
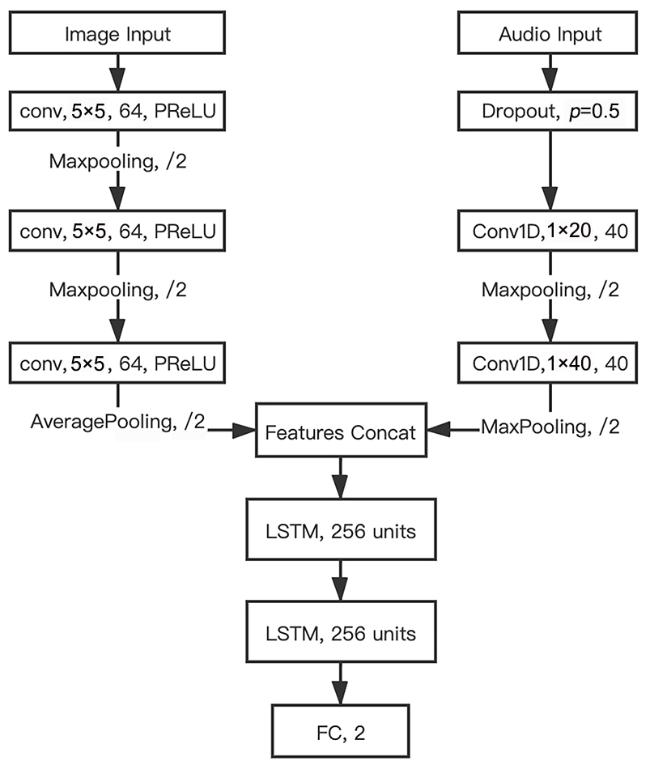
 Fig.1 Arousal⁃Valence spaceFig.2 Architecture of image model on RECOLA datasetFig.3 Architecture of voice feature extraction modelFig. 4 Architecture of image⁃voice joint model
Fig.1 Arousal⁃Valence spaceFig.2 Architecture of image model on RECOLA datasetFig.3 Architecture of voice feature extraction modelFig. 4 Architecture of image⁃voice joint model Table 1 Recognition of arousal and valence by the visual networks on RECOLA datasetTable 2 Recognition of arousal and valence by the speech networks on RECOLA datasetTable 3 Recognition of arousal and valence by the bimodal networks on RECOLA datasetFig.5 Face frame with high (left) and low (right) correlation coefficient
Table 1 Recognition of arousal and valence by the visual networks on RECOLA datasetTable 2 Recognition of arousal and valence by the speech networks on RECOLA datasetTable 3 Recognition of arousal and valence by the bimodal networks on RECOLA datasetFig.5 Face frame with high (left) and low (right) correlation coefficient/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}